인메모리 데이터베이스
- 디스크가 아닌 주 메모리에 모든 데이터를 보유하고 있는 데이터베이스
- 디스크 검색보다 자료 접근이 훨씬 빠름
- 디스크 방식은 디스크에 저장된 데이터를 대상으로 쿼리를 수행하지만,
- 인메모리 방식은 메모리상에 인덱스를 넣어 필요한 모든 정보를 인덱스를 통해 빠르게 검색
- 단점은 매체가 휘발성이라 DB서버 전원이 갑자기 꺼지면 안의 데이터가 삭제되기 때문에 날아가도 상관 없는 임시 데이터에 주로 사용 (로그인 세션)
- 지속성을 보장하기 위해 입력/수정/삭제된 값은 모두 디스크에 로그로 기록하며, 디스크로부터 로그 파일을 읽어와 메모리에서 재구축 하기도 함
- Redis, H2 …
Redis
- NoSQL에 속하는 데이터 방식이며, key-value 구조
- key-value 구조이기 때문에 별도 쿼리 없이 데이터 간단히 조회
- Data Expire 설정 가능
- String, List, Hash, Set, Sorted Set과 같은 다양한 자료구조 지원
- 캐시로 사용할 수도 있고, Persistence Data Storage로도 사용 가능
캐시 방식
캐시는 나중에 요청할 결과를 미리 저장해 두었다가 빨리 제공하기 위해 사용
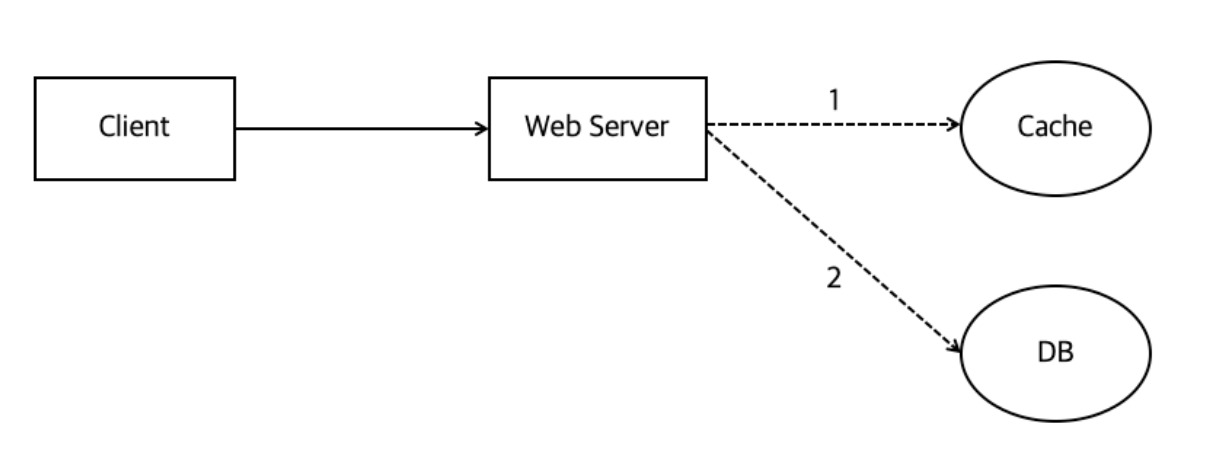
Look Aside Cache 패턴
- 웹 서버는 클라이언트 요청을 받아서, 데이터가 존재하는지 캐시를 먼저 확인
- 캐시에 데이터가 있으면 그걸 꺼내주고
- 없으면 DB에서 읽어 캐시에 저장한 후 클라이언트에게 데이터 돌려줌
Write Back 패턴
- 데이터를 캐시에 전부 저장해 두고, 특성 시점마다 한번 씩 캐시 내 데이터를 DB에 insert 하는 방법
- 속도가 빠르지만 캐시에 업데이트 하고 메모리에는 바로 업데이트 하지 않기 때문에, 캐시와 메모리의 값이 다른 경우가 발생
Persistence 방식
- 영속성을 보장하기 위해 데이터를 디스크에 저장할 수 있음
AOF(Append Only File) = 보관
- 입력/수정/삭제 명령이 실행될 때 마다 파일(appendonly.aof)에 기록(조회는 제외)
- 서버가 재시작 될 때 파일에 기록된 연산을 재실행하여 데이터 복구
- AOF를 계속 수행하면 기록되는 파일의 사이즈가 너무 커지지만, 특정 시점에 데이터를 다시 쓰는 rewrite를 수행해서 사이즈를 줄임
- 서버 장애가 발생해도 데이터 유실이 거의 없음
RDB(Redis Database) = 백업
- 특정 간격으로 메모리에 있는 데이터 전체를 디스크에 바이너리 형태로 기록
- AOF보다 사이즈가 작고, 로딩 속도 빠름
- 원하는 특정 지점의 데이터를 복구할 수 있어 재해 복구에 유용
- 서버 장애가 발생할 경우 저장하기 전 데이터가 유실될 수 있음
Redis 테스트
# Redis 서버 접속
$ redis-cli
# 전체 key 조회
$ keys *
# key로 value 조회
$ get ${KEY}
# key 추가
$ set ${KEY} ${VALUE}

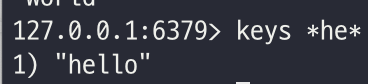
# key 검색
$ keys *${KEY}*
# key 삭제
$ del ${KEY}

'Database' 카테고리의 다른 글
| PostgreSQL 함수(Function) (0) | 2023.05.10 |
|---|---|
| PostgreSQL GIN Index (0) | 2023.01.30 |
| PostgreSQL 테이블 소유자 변경 (0) | 2023.01.11 |
| PostgreSQL Insert 할 때 Seq 조정 (0) | 2023.01.04 |
| PostgreSQL 테이블 청소 (0) | 2022.12.21 |